|
||||||
|
|||||||
|
|
|
NVIDIA 的 H200 GPU在 AI 社区引起了极大的轰动,它提供了显著更高的内存容量――大约是其前身 H100 的两倍。这些 GPU 共享强大的Hopper 架构,专为高效管理广泛的 AI 和 HPC 任务而量身定制。
NVIDIA H100一经推出,就为 AI 性能标准带来了重大转变。随着我们期待 2024 年 H200 的到来,人们对它超越 H100 成就的进步程度的好奇心也愈发强烈。深入研究它们各自的架构方面以及 Nvidia 对 H200 的预览,使我们能够评估最终用户的潜在性能增强。
NVIDIA H100 架构和规格
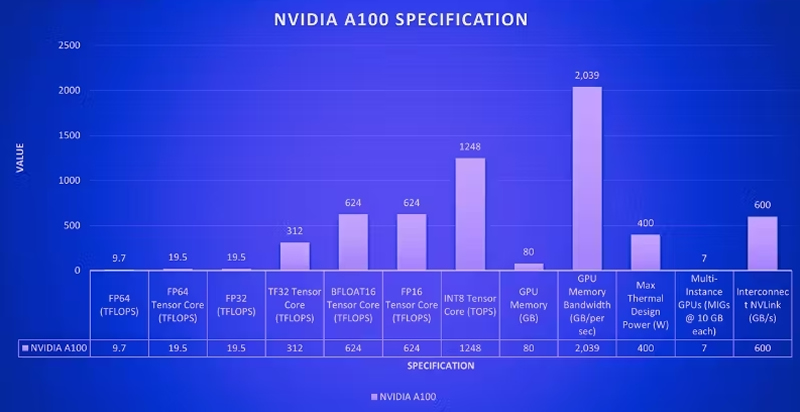
NVIDIA H100 是 NVIDIA 迄今为止功能最强大、可编程的 GPU,具有多项架构增强功能,例如与其前代产品 A100 相比具有更高的 GPU 核心频率和更强大的计算能力。
H100 引入了新的流多处理器 (SM),可处理 GPU 架构内的各种任务,包括: 执行 CUDA 线程,这是 NVIDIA 编程模型中的基本执行单元。 执行传统浮点计算(FP32、FP64)。 结合专用核心,如 Tensor Cores。
对于相同数据类型,H100 SM 执行矩阵乘法累加 (MMA)运算的速度是 A100 的两倍。此外,与 A100 SM 相比,它在浮点运算方面实现了四倍的性能提升。这是通过两项关键改进实现的: 1、FP8 数据类型: H100 引入了一种新的数据格式 (FP8),与 A100 的标准 FP32(32 位)相比,它使用 8 位,从而允许更快的计算,但精度略有降低。 2、改进的 SM 架构:由于内部架构的增强,H100 SM 对于传统数据类型(FP32、FP64)的处理能力本质上是其两倍。
H100 是最好的 GPU 吗?
NVIDIA H100 一经推出,就因其先进的架构、广泛的内存带宽和卓越的 AI 加速功能而被视为 AI 和 HPC 工作负载的顶级 GPU。它专为大规模深度学习、科学计算和数据分析而设计。然而,“最佳”GPU 可能会因具体用例、预算和兼容性需求而异。
H100 采用第四代 Tensor Core,性能较上一代 A100 有显著提升。
此外,H100 还引入了全新的 Transformer 引擎,专门用于加速Transformer 模型的训练和推理,这对于自然语言处理 (NLP) 至关重要。该引擎将软件优化与 Hopper Tensor Core 相结合,以实现大幅加速。
该引擎在两种数据精度格式(FP8 和 FP16)之间动态切换,以实现更快的计算和最小的精度损失,并自动处理模型内这些格式之间的转换以获得最佳性能。
与 A100 相比, H100 Transformer引擎在大型语言模型上提供高达 9 倍的 AI 训练速度和 30 倍的 AI 推理速度。
A100基准测试 NVIDIA H100 强大的 NVLink 网络互连可实现多达 256 个 GPU 在多个计算节点之间的通信,使其成为处理海量数据集和复杂问题的理想选择。安全 MIG 技术允许将 GPU 划分为安全、大小合适的实例,从而优化较小工作负载的服务质量。
NVIDIA H100 是第一款真正异步的 GPU,能够将数据移动与计算重叠,从而最大限度地提高整体计算效率。此功能确保 GPU 能够与处理任务并行执行数据传输,从而减少空闲时间并提高 AI 和高性能计算 (HPC) 工作负载的吞吐量。张量内存加速器 (TMA) 可进一步提高效率,从而优化 GPU 上的内存管理。通过简化内存操作,TMA 减少了管理内存带宽所需的 CUDA 线程,从而释放更多 CUDA 线程用于核心计算。
另一项创新是线程块集群,它将多个线程分组,以实现 H100 内多个处理单元之间的高效协作和数据共享。这扩展到异步操作,确保高效使用 TMA 和 Tensor Cores。此外,H100 引入了新的异步事务屏障,以简化不同处理单元之间的通信。此功能允许线程和加速器高效同步,即使位于不同的芯片部件上也是如此。
NVIDIA H100 与 H200 基准测试
在我们之前对 NVIDIA H100 的基准测试中,我们介绍了它的内存规格和其他功能。在本文中,我们将关注 NVIDIA H200。
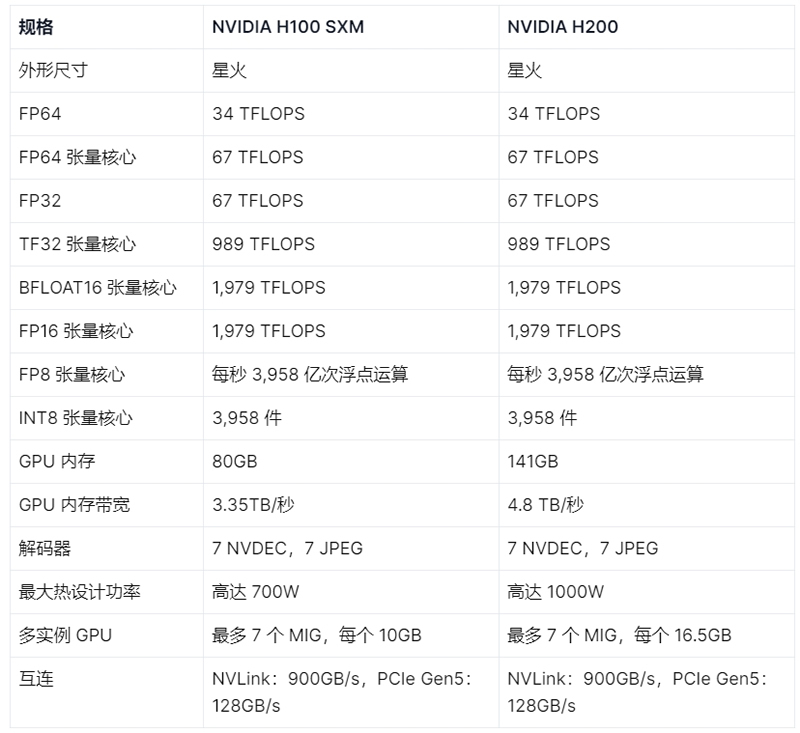
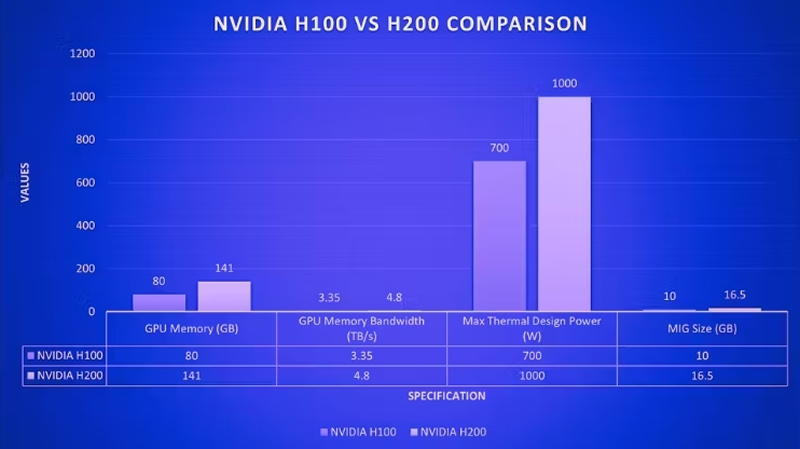
H200 基准测试 尽管 H100 令人印象深刻,但 H200 的功能更进一步。它是第一款采用HBM3e 内存的GPU ,内存容量高达 141 GB,几乎是 H100 的两倍。这种增加的内存大小对于 AI 至关重要,允许将更大的模型和数据集直接存储在 GPU 上,从而减少与数据传输相关的延迟。H200 还提供 4.8 TB/s 的内存带宽,与 H100 的 3.35 TB/s 相比有显着提升,从而能够更快地将数据传输到处理核心,这对于高吞吐量工作负载至关重要。
对于内存密集型 HPC 任务(例如天气建模),H200 的卓越内存带宽可促进 GPU 内存和处理核心之间更高效的数据流动,从而减少瓶颈并缩短洞察时间。据报道,HPC 任务的性能提升高达 110 倍,凸显了 H200 处理高度复杂模拟的潜力,使研究人员和工程师能够在更短的时间内取得更多成果。
NVIDIA H100 与 H200规格对比
H200 在 FP64 和 FP32 操作的性能指标上与 H100 相当,FP8 和 INT8 性能没有差异,达到 3,958 TFLOPS。这仍然令人印象深刻,因为 INT8 精度平衡了计算效率和模型准确性,使其成为计算资源有限的边缘设备的理想选择。
H200 提供增强的性能,同时保持与 H100 相同的能耗水平。通过将LLM 任务的能耗降低50% 并将内存带宽增加一倍,它有效地将总拥有成本 (TCO) 降低了 50%。
H200 比 H100 快多少?
NVIDIA H200 GPU 超越了 H100,在特定生成式 AI 和 HPC(高性能计算)基准测试中性能提升高达 45%。这一改进主要归功于 H200 的 HBM3e 内存容量增加、内存带宽增加以及热管理优化。性能增强的程度可能因特定工作负载和配置而异。
NVIDIA H100 与 H200 MLPerf 推理基准测试
让我们来看看 NVIDIA H100 与 NVIDIA H200 在MLPerf 推理分析方面的对比。MLPerf 基准测试是行业标准测试,旨在评估不同平台和环境中机器学习硬件、软件和服务的性能。它们为比较机器学习解决方案的效率和速度提供了可靠的衡量标准,帮助用户确定适合其 AI 和 ML 项目的最佳工具和技术。
NVIDIA H100 与 H200 MLPerf 推理基准测试 高级 AI 模型的开发人员需要测试他们的作品。推理对于大型语言模型 (LLM) 理解新的、未见过的数据至关重要。当呈现不熟悉的信息时,推理使模型能够根据其训练掌握数据中的上下文、意图和关系。然后,模型按顺序生成标记(例如单词)。
在推理过程中,LLM 利用获得的上下文和之前生成的标记来预测序列中的下一个元素。此过程使 LLM 能够生成全面的输出,无论是翻译句子、编写各种形式的创意文本,还是提供问题的全面答案。
在比较 H100 和 H200 在处理推理任务方面的表现时,我们关注的是它们在特定时间范围内能够生成的标记数量。这种方法为评估它们的性能提供了一个实用的指标,特别是在与自然语言处理相关的任务中。
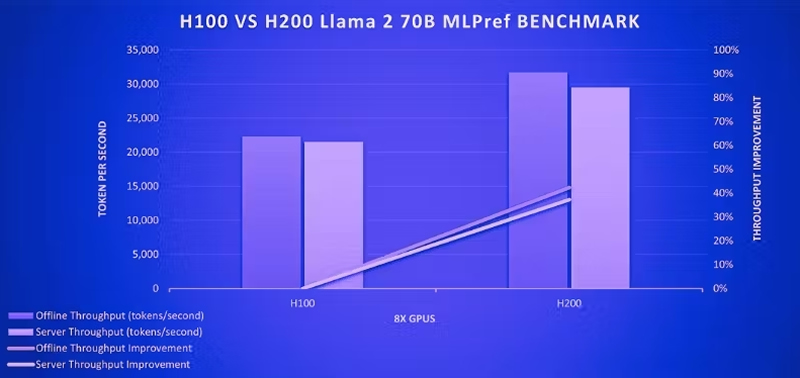
根据MLPerf Inference v4.0针对Llama 2 70B 型号的性能基准测试,H100 在离线场景下实现了 22,290 个令牌/秒的吞吐量。相比之下,H200 在相同场景下实现了 31,712 个令牌/秒的吞吐量,性能显著提升。
Llama 2 70B 型号的性能基准测试 在服务器场景下,H100的吞吐量达到了21504个Token/s,而H200的吞吐量达到了29526个Token/s,说明在服务器场景下,H200相比H100吞吐量提升了37%,性能提升非常明显。此外,在离线场景下,性能提升也非常明显。 NVIDIA H100 与 H200 吞吐量对比 原因概括如下:
1、H200 的内存和带宽提升: 与 H100 相比,H200 拥有更大的内存 (141GB) 和更高的带宽 (4.8 TB/s),分别约为 1.8 倍和 1.4 倍。这使得 H200 能够容纳更大的数据量,从而减少了从较慢的外部内存不断获取数据的需要。增加的带宽有助于加快内存和 GPU 之间的数据传输速度。因此,H200 无需借助张量并行或流水线并行等复杂技术即可处理大量任务。
2、H200 的推理吞吐量有所提升: 由于没有内存和通信瓶颈,H200 可以将更多的处理能力分配给计算,从而加快推理速度。在 Llama 测试中进行的基准测试证明了这一优势,即使在与 H100 相同的功率水平 (700W TDP) 下,H200 也能实现高达 28% 的提升。
3、H200 的性能提升: 基准测试表明,当功耗配置为 1000W 时,H200 在 Llama 测试中的性能提升幅度比 H100 高达 45%。这些比较凸显了 H200 GPU 相对于 H100 所实现的技术进步和性能提升,特别是在通过更大的内存容量、更高的内存带宽和改进的热管理来管理 Llama 2 70B 等生成式 AI 推理工作负载的需求方面。
关于我们 北京汉深流体技术有限公司是丹佛斯中国数据中心签约代理商。产品包括FD83全流量自锁球阀接头;液冷通用快速接头UQD & UQDB;OCP ORV3盲插快换接头BMQC;EHW194 EPDM液冷软管、电磁阀、压力和温度传感器及Manifold的生产。在国家数字经济、东数西算、双碳、新基建战略的交汇点,公司聚焦组建高素质、经验丰富的液冷工程师团队,为客户提供卓越的工程设计和强大的客户服务。 公司产品涵盖:丹佛斯液冷流体连接器、EPDM软管、电磁阀、压力和温度传感器及Manifold。 - 针对机架式服务器中Manifold/节点、CDU/主回路等应用场景,提供不同口径及锁紧方式的手动和全自动快速连接器。
|
|