|
||||||
|
|||||||
|
|
|
2024年OCP全球峰会于10月15日至17日在加利福尼亚州圣何塞举行,主题为“From Ideas to Impact”。此次峰会汇聚了全球领先的技术公司和行业专家,展示了在开放计算项目推动下数据中心硬件、AI基础设施和高效能计算领域的最新创新成果。
1、本届2024年全球开放计算峰会OCP聚焦AI和数据中心发展 2024年OCP全球峰会以“From Ideas to Impact”为主题,展示了开放计算项目通过开源和开放协作推动数据中心硬件创新的成果。自2011年成立以来,OCP专注于推动数据中心、服务器、存储设备等领域的进步。今年,OCP继续聚焦如何将技术理念转化为实际应用,推动全球数据中心的效率、可持续性和可扩展性。通过与全球社区的合作,OCP实现了从边缘计算到AI和机器学习等新兴技术的广泛部署。
2、芯片巨头推动AI基础设施的发展,英伟达公开其Blackwell系列平台设计。 英伟达在OCP峰会上公开NVIDIA GB200 NVL72的基础设计,其结合了多项创新,如高密度计算托盘、液冷系统和增强的电力管理。为简化开发流程,英伟达同时宣布了参与Blackwell系列的40家供应链合作伙伴。AMD展示了Alveo UL3422加速卡和锐龙AI PRO处理器,重点提高交易执行速度和AI处理性能。英特尔展示AI PC处理器和LLM解决方案,强调了开放标准在创新中的重要性。MARVELL、Credo和Astera Labs则通过新一代CXL连接技术和高速互连技术,推动AI和云基础设施的进步,ARM通过开源小芯片生态系统推动处理器的定制化和创新。
3、领先硬件供应商引领AI数据中心创新,立讯展示其核心零组件解决方案 1)AI服务器核心供应商方面:①立讯技术:在峰会上展示了其AI数据中心核心零组件解决方案,重点介绍了224G高速互连、热管理和电源管理系统,进一步提高了数据中心的效率和散热能力;②工业富联:旗下鸿佰科技展示NVIDIA HGX B200液冷AI加速器、GB200 NVL72与液冷CDU解决方案和最新超级运算中心模型等产品,同为鸿海旗下的鸿腾精密科技展示最新的AI数据中心连接技术及浸没式冷却解决方案;③超微电脑:推出全新集成NVIDIA BlueField-3 DPU的全闪存Petascale JBOF超大规模存储解决方案、液冷超级集群SuperClusters;④戴尔:发布了适用于高密度AI工作负载的机架级解决方案,如IR7000和PowerEdge服务器,专为大规模AI推理和训练而设计。 2)铜连接和高速互连技术领域:①安费诺:展示了最新的液冷技术和400 Gbps高速电缆;②莫仕:展示了用于高效可扩展数据中心的DC-MHS平台,提升了数据传输的效率和可扩展性;③泰科:展示了224G的AdrenaLINE Catapult和Slingshot背板连接器,为AI和网络应用提供了卓越的传输性能。这些技术推动数据中心在能效和散热能力上的提升以支持未来的AI工作负载。
一、OCP峰会背景 2024OCP全球峰会于10月15日至17日在加利福尼亚州圣何塞举行,以“从想法到影响”为主题,峰会将汇聚行业领袖、研究人员和创新者。 2024年OCP全球峰会的主题是“从想法到影响”。这一主题概括了开放计算项目的核心变革之旅。今年的主题反映了OCP致力于推动创新的承诺,这种创新超越了理论讨论,转化为现实世界的解决方案。随着技术发展的加速和开发周期的缩短,行业被迫迅速应对新兴趋势和需求。通过全球社区的集体专业知识,将远见卓识转化为突破性的技术,推动数据中心行业的开放性、效率、可持续性、可扩展性和增长。OCP专注于进步的不懈追求以及OCP社区驱动创新所能带来的深远影响。 OCP峰会是汇聚开放IT生态系统开发中最具前瞻性思维的顶级活动。该峰会为全球社区提供了一个独特的平台,分享见解、促进合作并展示开放硬件和软件的尖端进展。OCP的影响范围广泛,涵盖了整个数据中心生态系统——从存储和网络到诸如CXL和SONiC等新兴技术。这一全面战略确保了数据中心能够适应不断变化的技术和业务需求。 1)OCP历史:2011年,OCP成立,使命是将开源和开放协作的优势应用于硬件,快速推动数据中心及其网络设备、通用服务器和GPU服务器、存储设备及设备、可扩展机架设计等方面的创新。OCP的协作模式不仅限于数据中心,还被应用于推动电信行业和EDGE基础设施的发展。 OCP的核心是其由超大规模数据中心运营商组成的社区,同时加入了电信和托管服务提供商以及企业IT用户,他们与供应商合作开发开源创新,这些创新一旦嵌入产品后,就能从云端到边缘部署。OCP基金会负责促进和服务OCP社区,以满足市场需求并塑造未来,将超大规模驱动的创新推广到各个领域。通过开源设计和最佳实践,数据中心设施和IT设备嵌入OCP社区开发的创新,以提高效率、实现大规模运营和可持续发展,从而满足市场需求。塑造未来包括投资战略性项目,为IT生态系统应对重大变化做好准备,例如人工智能(AI)和机器学习(ML)、光学技术、先进的冷却技术和可组合硅等。
二、OCP参与厂商动态
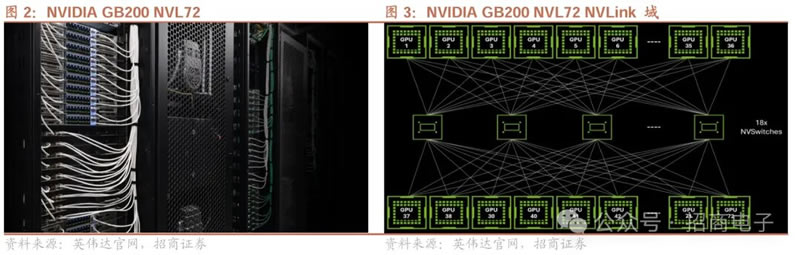
1、NVIDIA:在OCP公开Blackwell平台设计,以加速AI基础设施创新 1)NVIDIA在OCP公开NVIDIA GB200 NVL72设计:10月16日,在美国加利福尼亚州举行的OCP全球峰会上,NVIDIA宣布已把NVIDIA Blackwell加速计算平台的一些基础设计贡献给OCP,并扩大NVIDIA Spectrum-X对 OCP 标准的支持,以推动开放、高效、可扩展的数据中心技术的发展。 NVIDIA分享了NVIDIA GB200 NVL72系统电子机械设计中的关键部分,包括机架架构、计算和交换机托盘的架构、液冷和热环境规范以及 NVIDIA NVLink?电缆盒容量,以支持OCP社区,提高计算密度和网络带宽。此外NVIDIA Spectrum-X以太网网络平台也增添了对OCP社区规范的支持,在基于OCP认证设备的AI工厂,企业可以充分发挥出性能潜力,同时保证其软件的一致性。
2)NVIDIA提供的设计修改亮点:Rack reinforcements,为了在单个机架中高效容纳18个计算托盘、9个交换机托盘和4个 NVLink磁带,以支持5000多根铜缆,NVIDIA对现有机架设计实施了几项关键修改,调整可在机架内支持1 RU外形尺寸的19英寸 EIA 设备,从而将 IO 布线的可用空间增加一倍并提高托盘密度。增加了超过 100 磅的钢筋,显著提高了机架的强度和稳定性。结合后机架延长件以保护电缆支架和歧管配件。引入盲插滑轨和锁定功能,以促进NVLink安装、液体冷却系统集成,使用盲插连接器简化维护程序。 高容量母线,为了满足机架的高计算密度和增加的功率要求,为增强型高容量母线开发了新的设计规范。升级后的母线保持了与现有 ORV3 相同的宽度,但具有更深的轮廓,显着增加了其载流量。此增强功能可确保母线能够有效地处理现代高性能计算环境的高功率需求,而无需在机架内提供额外的水平空间。 NVLink Cartridge,为实现NVLink域中所有72个NVIDIA Blackwell GPU之间的高速通信,其中四个NVLink Cartridge垂直安装在机架后部,可容纳5000多根有源铜缆,提供130 TB/s和260 TB/s AllReduce带宽的聚合All-to-All带宽。 液冷板和浮动盲孔配合,为有效管理机架所需的120 KW 冷却能力,实施直接液体冷却技术。开发了一种增强的Blind Mate液体冷却歧管设计,能够提供高效的冷却。创造了一种新颖的浮动盲插接盘连接,有效地将冷却液分配到计算和开关托盘,显著提高液体快速插拔接头在机架中对齐和可靠插接的能力。 计算和交换机托架机械外形规格,为了适应机架的高计算密度,引入了1RU液冷计算和交换机托盘外形尺寸。开发了一种新的、更密集的DC-SCM设计,比当前标准小 10%。采用了更窄的母线连接器,以最大限度地利用可用的后面板空间。 3)新联合NVIDIA GB200 NVL72参考架构:在 OCP 上,NVIDIA 宣布与 Vertiv 联合推出的全新 GB200 NVL72 参考架构,Vertiv 是电源和冷却技术的领导者,也是设计、构建和服务高计算密度数据中心的专家。新的参考架构将显著缩短部署 NVIDIA Blackwell 平台的 CSP 和数据中心的实施时间,使得数据中心无需为 GB200 NVL72 开发自己的电源、冷却和间距设计。通过利用Vertiv在节省空间的电源管理和节能冷却技术方面的专业知识,数据中心可以在全球范围内部署 7MW GB200 NVL72 集群,将实施时间缩短多达 50%,同时减少电源空间占用并提高冷却能效。 4)数据中心的关键基础设施:随着全球从通用计算过渡到加速计算和 AI 计算,数据中心基础设施正变得日益复杂。为了简化开发流程,NVIDIA 正在与 40 多家全球电子制造商密切合作,以提供创建 AI 工厂的关键组件。 众多合作伙伴正在 Blackwell 平台上进行创新和构建,其中包括 Meta。Meta 计划将其基于 GB200 NVL72 的 Catalina AI 机架架构捐赠给 OCP。为计算机制造商提供了灵活的选择,使其能够搭建出高计算密度系统并满足数据中心日益增长的性能和能效需求。
2、AMD:以纤薄尺寸电子交易加速卡扩展 Alveo 产品组合,助力普适且具性价比的服务器部署 1)AMD Alveo UL3422:为交易商、做市商和金融机构提供了一款针对机架空间和成本进行优化的纤薄型加速卡,旨在快速部署到各种服务器中。Alveo UL3422 加速卡由 AMD Virtex? Ultra Scale+? FPGA 提供支持,采用新颖的收发器架构,具备硬化且经过优化的网络连接核,专为高速交易定制打造。可实现超低时延交易执行,达到低于 3 纳秒的 FPGA 收发器时延和突破性的“tick-to-trade”性能。 2)锐龙AI PRO 300系列处理器:赋能下一代商用PC,采用全新AMD “Zen 5”架构,适配Copilot+企业PC的商用处理器系列产品,通过XDNA 2架构为集成的NPU提供动力,拥有领先的50+ NPU TOPS AI处理能力,基于4nm工艺和创新的电源管理,提供了更长的电池续航。 3)AMD EPYC 9005:采用“Zen 5”核心架构,兼容广泛部署的SP5平台,可提供从8到192核心数量的广泛配置,进一步提高了性能和能效。64核的AMD EPYC 9575F为基于GPU驱动而对CPU能力要求苛刻的AI解决方案量身定制。该处理器最高可提供5GHz频率,从而满足在严苛的AI工作负载中支持GPU持续提供所需数据。 3、英特尔:强调开放标准在将创意转化为技术方面的关键作用 1)首款AI PC台式机处理器酷睿Ultra 200S:将AI PC功能扩展至台式机平台,桌面级AI PC。该处理器系列包括英特尔? 酷睿? Ultra 9 285K处理器等5款未锁频台式机处理器,拥有最多8个全新的疾速性能核,以及最多16个全新的能效核,与上一代相比将多线程工作负载性能提升最高达14%。 2)LLM与企业数据知识库连接:虽然基础模型具有巨大潜力,但要为企业带来最大价值,还必须与企业专属和领域特定的数据相结合。通过RAG(检索增强生成),英特尔致力于弥合企业数据与AI模型之间的差距,提升LLM(大语言模型)的输出效果,并帮助企业根据其专有数据定制LLM,而无需重新训练或微调。 通过LLM与企业数据知识库连接为企业提供实用且安全的数据管理方式,确保AI系统能够高效地融入企业的日常运营。Intel AI for Enterprise RAG解决了企业在RAG部署过程中面临的可扩展性、易用性、TCO、安全性和开放性挑战。
4、立讯技术:展示最新的AI数据中心核心零组件解决方案 立讯技术最新的AI数据中心核心零组件解决方案,展示了公司众多的前沿技术与尖端产品,并且把它们集成在了Orv3标准机柜中,代表了立讯技术在数据中心领域多年深耕的结晶,它不仅仅是产品的展示,更是一次重大的技术理念创新,借鉴了数据中心资源池化的理念,以端到端功能链的全新视角,重新思考未来数据中心零组件的发展模式,可以从三个功能维度来看: 1)224G高速互连系统: 2)冷板液冷系统: ①Coldplate:冷板设计在效率与可靠性方面均超越行业标准,标准化流程与精确数据控制确保了产品质量的一致性与应用性能的最优化,为数据中心提供高效散热解决方案; 3)大功率直流电源系统: ①Busbar & Clip:直流母排通过型材绘制定制超大横截面,满足各种电流需求。表面采用镍底镀与厚银镀处理,降低了接触电阻,确保了Clip插拔的稳定可靠及耐久性,为数据中心提供稳定可靠的电力供应;
5、工业富联:展示B200液冷AI加速器、GB200 NVL72与水对水CDU解决方案 工业富联旗下鸿佰科技展示NVIDIA HGX B200液冷AI加速器、GB200 NVL72与水对水CDU解决方案和最新超级运算中心模型等产品。工业富联旗下鸿佰科技出席OCP,展示其全面集成的AI产品线,为未来AI数据中心赋能。鸿佰提供从服务器到机柜乃至数据中心集成的全面创新,以提升现代数据中心的能源效率和服务效能。鸿佰展示的NVIDIA HGX B200液冷AI加速器提供强大AI训练效能,可无缝完美整合至OCP ORv3机架中,并部署于客户的数据中心。鸿佰还展出NVIDIA GB200 NVL72与水对水CDU解决方案。GB200 NVL72是专为兆级参数大语言模型训练和实时推论设计的液冷机柜,相当于拥有72个NVLink连接的Blackwell Tensor 核心GPU的巨型GPU。此设计帮助企业及组织得以充分发挥AI潜能,推动各领域创新应用。而高效能水对水CDU解决方案则提供卓越冷却能力,可支持多达10台GB200 NVL72,为下一代AI数据中心的发展奠定坚实基础。此外,在现场还可以看到鸿佰的最新超级运算中心模型,展望未来AI基础设施的发展趋势。该设施实际部署以GB200 NVL72丛集为主,规划总计超过1000个GPU,旨在应对未来最严苛的AI工作负载。这个中心专注于AI效能调校及优化,充分彰显鸿佰在推动AI尖端创新方面的坚定承诺。 同为鸿海旗下鸿腾精密科技展示最新的AI数据中心连接技术及浸没式冷却解决方案。鸿腾精密科技(FIT)在OCP Global Summit 2024展示最新的AI数据中心连接技术及浸没式冷却解决方案。鸿腾精密所展示的创新连接解决方案,包括定制化224G+ XPU/GPU 连接插槽、共同封装铜缆及光纤架构、ORV3电源线缆等。相关解决方案不仅可改善AI机柜信号完整性和优化数据传输,同时也能有效整合先进冷却模块的相关技术。除了AI连接解决方案之外,鸿腾精密也展示浸没式冷却IT平台解决方案。
6、超微电脑:推出全新集成NVIDIA BlueField-3 DPU的全闪存Petascale JBOF超大规模存储解决方案、液冷超级集群SuperClusters 推出全新千万亿次JBOF全闪存存储解决方案,集成NVIDIA BlueField-3 DPU 实现AI数据管道加速。该JBOF(Just a Bunch of Flash)系统在2U机箱中集成多达四个NVIDIA BlueField-3数据处理单元(DPU),以运行软件定义的存储工作负载。每个BlueField-3 DPU都支持400Gb以太网或InfiniBand网络,并具备硬件加速能力,适用于处理诸如加密、压缩和纠删编码等计算密集型存储和网络工作负载,以及扩展AI存储需求。该双端口JBOF架构采用了最先进的主动-主动集群设计,确保关键任务存储应用的纵向扩展以及对象存储和并行文件系统等横向扩展存储的高可用性。Supermicro的JBOF解决方案结合了NVIDIA BlueField-3,将传统的存储CPU和内存子系统替换为BlueField-3 DPU,并在DPU的16个Arm核心上运行存储应用程序。除了存储加速功能,如纠删码和解压算法,BlueField-3还通过硬件支持RoCE(基于以太网的远程直接内存访问)、GPU直接存储和GPU发起存储来加速网络性能。 Supermicro推出面向人工智能数据中心推出的液冷超级集群,采用NVIDIA GB200 NVL72和NVIDIA HGX B200系统。Supermicro 业界领先的端到端液冷解决方案由 NVIDIA GB200 NVL72 平台提供支持,可在单个机架中实现百亿亿次计算,并已开始向特定客户提供样品,以便在第四季度末全面生产。此外,最近宣布的 Supermicro X14 和 H14 4U 液冷系统和 10U 风冷系统已准备好用于 NVIDIA HGX B200 8-GPU系统。Supermicro 的液冷 SuperClusters 适用于基于 NVIDIA GB200 NVL72 平台的系统,采用新型先进机架内或行内冷却液分配单元 (CDU) 和专为计算托盘设计的定制冷板,该计算托盘在 1U 外形中容纳两个 NVIDIA GB200 Grace Blackwell 超级芯片。Supermicro 的 NVIDIA GB200 NVL72 借助 Supermicro 的端到端液冷解决方案,在单个机架中提供百亿亿次 AI 计算能力。机架解决方案包含 72 个 NVIDIA Blackwell GPU 和 32 个 NVIDIA Grace CPU,通过 NVIDIA 的第五代 NVLink 网络互连。NVIDIA NVLink Switch 系统以极低的延迟实现 130 TB/s 的总 GPU 通信,从而提高 AI 和HPC工作负载的性能。此外,Supermicro还支持最近发布的NVIDIA GB200 NVL2平台,这是一款2U风冷系统,配备紧密耦合的两个NVIDIA Blackwell GPU和两个NVIDIA Grace CPU,适合轻松部署各种工作负载,例如大型LLM推理、RAG、数据处理和HPC应用程序。
7、Marvell:展示3nm PCIe Gen 7加速基础设施技术 1)Structera CXL设备产品线:在AI和云应用程序中,通常需要比标准服务器提供的更多内存容量和带宽,这导致了性能低于预期、完成时间延长及资源使用效率低下的问题。为了解决这些挑战,Marvell推出了新的Structera CXL设备产品线,使数据中心运营商能够以高效、经济的方式为服务器增加更多内存和/或计算能力。Structera A CXL近内存加速器将服务器级处理器内核与多个内存通道相结合,显著提升深度学习或机器学习等高带宽任务的内存带宽。 2)AI和云连接领域的DSP连接解决方案:AI的快速部署正在改变数据中心的网络拓扑和部署方式,带宽的指数级增长、计算集群规模的扩大以及定制架构和更快的升级周期,都在推动AI网络内部对连接的多样化需求。基于DSP的连接解决方案在优化连接方面发挥着关键作用,能够根据应用的规模和周期时间进行部署。 3)3nm PCIe Gen 7:该技术的数据传输速度是PCIe Gen 5的两倍,使得在加速服务器平台、通用服务器、CXL系统和分散基础设施内的计算织物能够持续扩展。此外Marvell还展示了其加速基础设施产品组合,包括Alaska 1.6T PAM4 DSPs、Alaska PCIe Gen 6重定时器和Gen 7 SerDes、COLORZ 800 ZR/ZR+模块、Nova和Spica PAM4 DSP、Orion相干DSP以及Teralynx以太网交换机。
8、Credo:宣布推出新PCIe 6和PCIe 7重定时器以追求更高性能与更低成本 1)新PCIe 6和PCIe 7重定时器:基于Credo的串行器/解串器(SerDes)技术构建,提供行业领先的性能和能效,同时构建在比竞争器件成本更低、更成熟的工艺节点上。随着整个数据基础设施市场数据速率和相应带宽需求的增加,该解决方案可以提高能源效率。Credo 展示PCIe 6/7具有线性接收光学 (LRO) 功能的800G低于10W OSFP光模块,可与51T交换机和标准DSP模块互连。 2)现场演示PCIe和CXL互连:通过Credo OSFP-XD PCIe AEC连接到 XConn PCIe 5 交换机的AMD EPYC服务器,XConn交换机进一步驱动两个NVIDIA H100 GPU机箱。使用MemVerge的Memory Machine X软件演示机架级 CXL2.0 共享内存系统,展示AMD EPYC 9005服务器通过Credo CXL AEC连接到XConn CXL交换机XConn CXL交换机连接到两个装满 CXL 内存的机箱——一个基于SMART Modular的CEM AIC外形尺寸,一个基于Micron的E3外形尺寸,使服务器能够使用CXL.mem协议完全访问和共享 CXL 内存。
9、Astera labs:强调连接性仍是人工智能需要改进的关键领域 1)CXL Interconnect Fabric:为充分利用GPU的资源并释放AI的全部潜力,必须建立强大的AI基础设施连接系统,而不仅仅是追求更快的速度和数据传输能力。能够满足AI应用程序和需求的多样性,加快AI平台的开发周期,CXL Interconnect Fabric提供深度系统可见性和诊断功能,最大限度地提高正常运行时间和资源利用率。 2)Aries PCIe/CXL智能DSP重定时器:在所有主要的超大规模和人工智能平台提供商中进行了现场测试和广泛部署,通过可靠的 3 倍扩展解决 AI 和通用服务器中的高速 PCIe?/CXL? 信号完整性挑战,专为 AI 和云基础设施而构建,提供高性能、低功耗和无缝互操作性。
10、ARM:基于小芯片生态系统促进多供应商合作 Total Design小芯片生态系统:ARM详细介绍Total Design小芯片生态系统的最新进展,展示如何通过开源固件进一步推动定制芯片的发展。特别强调其Neoverse CSS的发展与开源固件(如TF-A、SCP、MCP、EDK2和OpenBMC)的结合,这些构建块对于开发定制的云原生处理器和AI加速器至关重要。深入探讨开源固件在快速变化的AI创新环境中的作用,展示AMI在OCP社区中的贡献,包括Boot、BMC和PRoT项目。
11、安费诺展示最新液冷技术与400 Gbps高速连接电缆 1)液冷:Amphenol展示了OSFP1x8外壳和连接器上的液冷冷板技术演示,以及与Alphawave Semi合作的现场演示,展示EXAMAX2 ARK板对板背板接口运行的真实112GbE PAM4流量,同时完全浸没在冷却液中;
12、Molex:为高效可扩展的数据中心基础设施创建提供创造性的设计 1)标准化效率与可拓展性的DC-MHS: 为优化数据中心性能和适应性DC-MHS提供了统一框架。DC-MHS通过为物理基础设施组件制定协议,为模块化、互操作性和适应性强的数据中心奠定了基础。该规范涵盖了关键元素,如机架、电源分配单元和冷却系统。 DC-MHS推进的关键进展之一是对PCIe Gen6的支持,随着行业向更高的数据传输率和更大的带宽发展,这一组件变得尤为重要。通过标准化物理基础设施并确保无缝集成,DC-MHS使数据中心能够充分利用PCIe Gen6的功能,这对于下一代应用至关重要。这一重点不仅使数据中心能够应对当前需求,还确保了未来创新的可扩展性,巩固了DC-MHS作为数据中心架构演变中的基石地位。 M-XIO/PESTI:M-XIO/PESTI标准化了数据中心的外围设备连接,解决了高速数据传输和信号完整性等挑战。直接到接触的端接策略消除了电缆组件中的电路板,使自动化更具可重复性和可靠性,并实现了从系统内任何地方到ASIC附近的直接连接。Molex的NearStack PCIe连接器系统提供了一种高性能解决方案,能够满足苛刻外围应用所需的带宽和可靠性。该连接器的间距较小且接合高度较低,在系统内占用最小空间,缓解了空间限制。 M-PIC:M-PIC致力于为主处理器模块(HPM)创建一个统一的基础设施连接模型,解决电力传输、信号完整性和空间限制等问题。Molex的KickStart连接器系统提供了一种独特的解决方案,结合了信号和电力,提供了具有紧凑、可靠设计的强大、可扩展的解决方案。Molex的Micro-Fit+和Pico-Clasp连接器为HPM和机箱内的各种电力和信号连接提供了多功能选项。作为一个一体化系统,KickStart是第一个符合OCP标准的解决方案,将低速和高速信号以及电路电源集成在一个电缆组件中。 2)开放加速器基础设施:OAI框架旨在规范加速器平台,简化多种技术在数据中心的集成。通过建立通用基础设施规范,包括通用主板和预定外形尺寸,OAI允许数据中心运营商无缝整合各种加速器技术。这种标准化鼓励创新,降低开发成本,并提高运营效率。除了硬件外,OAI还强调软件兼容性,确保加速器能够与现有操作系统无缝协作。OAI对加速器集成的全面方法支持异构加速器应用的部署,充分释放AI、机器学习和高性能计算工作负载的潜力。 3)现代数据中心基础ORV3:一种标准化平台,旨在提高数据中心的效率和可扩展性。通过为机架、电源分配单元(PDU)和冷却系统制定通用规范,ORV3帮助数据中心运营商构建灵活且适应性强的基础设施。这种硬件的一致性有助于各种组件之间的互操作性,降低复杂性并加快部署速度。 ORV3着重于增强电源效率、改善气流并简化机架环境中的电缆管理。通过预设的机架尺寸、电力传输和冷却配置,ORV3使数据中心能够实现更高的服务器密度、更低的运营成本和整体性能的提升。
13、TE Connectivity:展出224G架构、液冷、数据中心机架等高速连接解决方案
1)224G架构赋能AI与网络:TE展示了电缆背板架构加上OTB和近芯连接,采用224G AdrenaLINE Catapult近芯连接器和AdrenaLINE Slingshot电缆背板连接器(电缆对电缆和电缆对板),该演示由Marvell的224 Gbps DSP SerDes硅片驱动。
14、SK Hynix:展示包括HBM3E等在内的领先AI和数据中心内存产品 SK Hynix在2024年OCP全球峰会上展示其领先的AI和数据中心内存产品,包括HBM3E、CXL Memory Module(CMM)、DDR5 RDIMM和MCR DIMM服务器DRAM以及企业级SSD(eSSDs)。推动AI内存和存储解决方案方面的创新以及AI和数据中心运营的转型。
15、Hyve Solutions:推出先进网络交换机和Orion产品线,加速AI部署 1)先进网络交换机:部署在加速机架级AI,以满足对高性能AI工作负载的快速增长需求,交换机集成Broadcom的Tomahawk? 5系列51.2 Tb/s设备,能够将客户特定的需求高效地集成到产品中,帮助组织更快、更有效地部署AI技术。 16、ASUS展示基于NVIDIA和AMD的AI解决方案 1)先进的AI服务器解决方案:方案分别基于NVIDIA Blackwell平台和AMD EPYC 9005处理器以及Instinct MI325X加速器。基于NVIDIA技术的ESC AI POD是一个创新的机架解决方案,集成了NVIDIA GB200 NVL72系统,提供高达36个NVIDIA Grace CPU和72个NVIDIA Blackwell GPU,旨在加速大型语言模型推理。此外,ASUS还展示了支持高达八个NVIDIA H200 Tensor Core GPU的8000A-E13P 4U服务器,针对AI进行了优化。 16、LITEON:推出NVIDIA驱动的AI云服务器机架解决方案 集成AI云服务器机架解决方案:方案融合了高性能电源、全面液冷系统、集成机械设计、智能电源管理软件和软硬件系统集成五大关键技术。提升数据中心在AI时代的高性能计算、能效管理和冷却性能,助力客户实现低碳绿色数据中心的能源管理目标。LITEON的液冷解决方案显著提高冷却效率,降低能源和碳足迹消耗。同时LITEON展示了集成机柜电源系统和解决方案,提供97.5%的高密度电源转换效率,满足AI服务器的高性能计算应用需求,并配备智能电源管理系统,实现数字管理和远程实时监控。
17、戴尔:推出为AI设计的全新机架级解决方案IR7000、PowerEdge M7725和XE9712 戴尔宣布推出专为节能、密集计算和大规模人工智能而设计的全新机架级解决方案IR7000、PowerEdge M7725和XE9712。戴尔的集成机架可扩展系统IRSS符合开放计算项目的机架标准,并通过增强的能源效率和可扩展性支持数据中心运营。IR7000(Integrated Rack 7000)是一款基于21英寸Open Rack Version 3(Orv3)的机架基础设施,具有密集计算和液体冷却功能,适用于高TDP GPU和CPU。在ORV3之前,直接液体冷却(DLC)歧管连接是专有的,当尝试在单个机架中添加具有不同DLC OEM的服务器时,它们不兼容。Del的下一代快速连接模块化基础设施为训练大型AI模型的高性能工作负载确定了未来的方向。PowerEdge M7725专为密集计算而设计,支持两个AMD EPYC第5代处理器,与前几代处理器相比,可为高性能计算提供高37%的每时钟指令数。单个IR7000可容纳72个M7725服务器节点,每个机架可提供多达27000个内核。M7725通过前置IO以及无线电源和DLC连接提供了更好的可维护性。配备IR7000机架的M7725通过戴尔独有的后门热量捕获技术实现了接近100%热量捕获能力。 PowerEdge XE9712通过NVIDIA GB200 NVL72 解决方案扩展了Dell AI Factory。在配备8路HGX GPU的XE9680成功的基础上,XE9712提供了更快的LLM性能,72个GPU作为一个GPU运行在单个机架中,将大规模部署为超级POD,机架之间具有完整的网络连接,并由Dell的turnkey机架规模部署服务、供应链和物流提供支持。
18、Meta:展示面向AI基础设施的开放式架构Catalina
Meta展示面向AI基础设施的开放式架构Catalina 等产品。Meta宣布即将发布Catalina,这是专为AI工作负载设计的全新高性能机架。Catalina基于NVIDIA Blackwell平台全机架解决方案,重点关注模块化和灵活性。它旨在支持最新的NVIDIA GB200 Grace Blackwell超级芯片。借助Catalina,Meta推出了Orv3,这是一款高功率机架,能够支持高达140kW的功率。完整的解决方案采用液体冷却,由支持计算托盘、交换机托盘、Orv3 HPR、Wedge 400结构交换机、管理交换机、电池备用单元和机架管理控制器的电源架组成。此外,Meta扩展了Grand Teton平台以支持AMD Instinct MI300X,以及展示下一代 AI 集群提供的新型分解式调度结构。
关于我们 北京汉深流体技术有限公司是丹佛斯中国数据中心签约代理商。产品包括FD83全流量自锁球阀接头;液冷通用快速接头UQD & UQDB;OCP ORV3盲插快换接头BMQC;EHW194 EPDM液冷软管、电磁阀、压力和温度传感器及Manifold的生产。在国家数字经济、东数西算、双碳、新基建战略的交汇点,公司聚焦组建高素质、经验丰富的液冷工程师团队,为客户提供卓越的工程设计和强大的客户服务。 公司产品涵盖:丹佛斯液冷流体连接器、EPDM软管、电磁阀、压力和温度传感器及Manifold。 - 针对机架式服务器中Manifold/节点、CDU/主回路等应用场景,提供不同口径及锁紧方式的手动和全自动快速连接器。
|
|