|
Ӣΰ���ع���AIоƬH20����!
�¼���NvidiaӢΰ��Ի����ع��桱AIоƬH20���ն˲�Ʒ�ѿɽ���Ԥ�������ݲݸ����У������ۼ۸�����������Ԥ����1.3-1.4�����𣬹��������Ҵ�����Ӣΰ���¶����ɹ�����ƬH20���ֹ�Q2������ȫ��H20���������ܻ��ڴ�ʮ��Ƭ��֮ǰ���г�Ԥ��Ӧ����30��Ƭ���ҡ�ͬʱ��Ӣΰ����һ�й��ع���оƬL20 PCIEĿǰҲ�ڲ����У����������ɹ���
�¼���Ӣΰ��Ի����ع��桱AIоƬH20���ն˲�Ʒ�ѿɽ���Ԥ�������ݲݸ����У������ۼ۸�����������Ԥ����1.3-1.4�����𣬹��������Ҵ�����Ӣΰ���¶����ɹ�����ƬH20���ֹ�Q2������ȫ��H20���������ܻ��ڴ�ʮ��Ƭ��֮ǰ���г�Ԥ��Ӧ����30��Ƭ���ҡ�ͬʱ��Ӣΰ����һ�й��ع���оƬL20 PCIEĿǰҲ�ڲ����У����������ɹ���
�����������Ʒdz���ȷ��������ע����������������Ϊ�����Ҵ���H20�Ĵ�����������������������������������������ȷ�Ҳ�����ġ�һ���棬�ҹ���оƬ��������֧������ǿ������������оƬ����������������ʵ�������ܵõ������������һ���棬�������������������Ի��Ʋã�����1���������Ƕ���ս��ҹ���ȡ�Ƚ�����������;����

�����������DZ���֮·������оƬռ�ȳ�������
������ 23��24���ҹ�AIоƬ�г�����ռ�����������оƬռ�ȿ��ܴ�ȥ��25%����������40%��45%��
�˴�H20�����ϳ�Ԥ�ڡ������ע�й�NV��ȥ��������������H20�ڻ����۵�Ԥ�ڽ�Ϊ���ۣ��˴����ҴĶ����ϳ�Ԥ�ڣ������ע�˳���Ϣ���Ϲ�ɷݵ���ر�Ľ��������ע��������
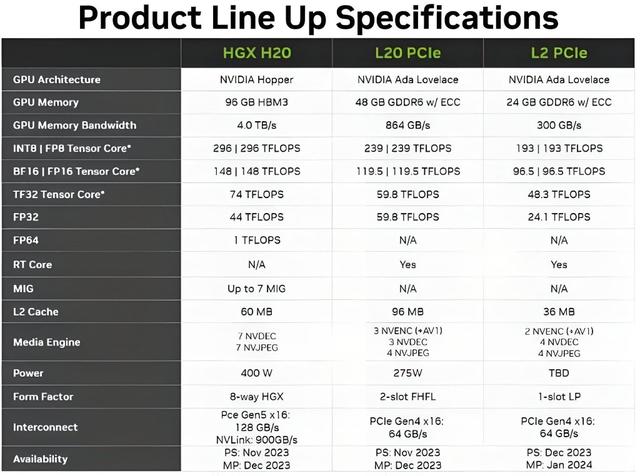
H20���Ǹ��桢�ߴ����������������ܲ����Ҫ��M�������Ҫ������ơ�H20���������ܲ��Լ��HW�N��910������һ�룬����������DZ�910B�ߣ�������910B������NV��NVlink�ܹ���Ӣΰ��Ŀ���ͨ���ʹ�á���ѵ�ģʽ�������HW�ĸ������Ŀ����⡣����910B��������A100�����ܽӽ���1�����ڵĿ����ǻ��������������䡢AI������������2��������̬�������졣Ӣΰ��Ŀ�����������ߵĻ������Ƴ��ģ��ڻ���������CUDA��̬�����ġ�
Q&A
Q��H20��H800��ѵ����6-7�ɡ�ԭ��H��ʱ������ʹ��Ч����3-4�ɣ��µ�H20�Ӵ��������ɼ�Ⱥ�Ĵ�ģ��ѵ��Ч�ʿ��ܱ�H800������
A����������ѵ����ܱȽ�����������GPT1.0\2.0�ܹ�Ϊ����H800�������ܸܺߣ��������ڼ������ѵ����������û�а취ʹ��������H800ʹ��Ч�ʺܵ͡�����H20���棬������ȡ��ѵ���������Ǻܸߵķ��棬���ʺ϶�ѵ�����AI��������ʹ�á�
Q��������оƬ�Ǹ����״�ģ��ѵ������
A�����ڴ�ģ��ѵ�����棬���ܵ�����Ӳ����һ�ǿ������ǿ�ܡ�GPT4.0�ǻ���������������֪ʶ��������3.0��4.0��û�취�ã�������������1.0/2.0��ѵ�����������ܶ������ˡ���ʹH100�п�Ҳѵ������������Ϊ�ײ������о��ޡ�Ӣΰ���Ƴ�H20�Ŀ����ǿ���ͨ�����ڿͻ�����ʵ����A100��H800ͬ��Ч�ʡ�NV���Զ����������������Ҳ�����û���GPT2.0ѵ��ģ�Ϳ��ѵ�������ߵ�ģ�ͣ����ģʽҲ��һ�ٶ�õġ�NV������ȫ�ж�NV����ڵ�������Ӳ�����Ը����������������жϣ�����û�취��ǧ�ڼ�ѵ��ģ�͵Ŀ�ܡ� NV��IB����������ģ���400G\800G���DZ���ġ���ΪH100 AI��������������400G��ģ�飬Ҳ����800G��8�ſ���4��800G��ģ�飩����ΪAI�������������ˣ���ģ������Ҳ���ġ��������棬��NV��ib����������������������̫����������
Q��H20��Ʒ��HBM3��һ��������3��������������A100��30%��HBM����һ����
A��������HBM����H800�����H20��cowos���Ƴ���800��ȸ������������ߵͣ����ھ�Ԫ�Ƴ̣�nmԽ�ͣ����ɶ�Խ�ߣ�����Խǿ��H20��������������ƹ�����һ�㣬������910B��������ƹ��պá����������ԣ�������һЩ�Ƚϲ�����칤�������ã��ɱ��½��ˡ�Ψһ��HBM�ĺ��ˣ���ֵ��3����
Q��H20��NVLINK��900GB/S��H800ֻ��400�����Դﵽ��
A��NVLINK��NV���Ǹ߶˵ģ��ܳ����ˣ�Hϵ�ж�����֧�š��������֧����ô���������Ŀ��ﵽ��nvlink�Ĵ����ٶȿ������ȵġ��N�ڴﲻ���ģ�������400G��8��һ������200�ˡ�
Q��ѵ�������ָ��
A��ѵ��ģ�Ͷ��������Կ��֧�ţ�������ܡ��������»���������������������ѵ�����Կ�ܷ��棬�����汾�Ƚϵͣ�Ϊ1.0��2.0������������GPT 4.0�汾��API�˿ڲ��������˻��������ã���������4.0�����������ܡ���������A100\H100�Dz�Ը��������칤�ա�
Q��ΪʲôH20������Ҫcovos��װ��
A��������HBM������cowos��4��3nm���ϣ��Ǹ߶˷�װ������A100\A800\H20�����칤�ղ���H100��ô�ߣ����Է�װ�ܹ�����Ҫcowos���ɱ��½�������H100����������ʢ�����Բ���Ϊ���й�������ռ�÷�װ���ܡ�
Q������������Ӱ�죿
A����ǰ����A\H800���������ڶ��ڽ����Ժ���������ͣ���ˡ�����NV�Ƴ�H20�Ժ����齨�������ġ������������ġ�����ͨ��NVLINK��IB����ܹ���ʹ�ö���H20���������H20��AI����������������ġ���������˾�ǻ���cuda�ܹ��ģ�H20�ij��ֻ���������������Ļ����������Ĵ��ȱ�������
Q���Dz��ǿ�������Ϊ���������Ķ�ȱ�������������Ǽۣ�����������˾ƫ���գ�
A��������˾�����������յ�״̬������������ҵ�Կ��������Ժ�ǿ��û������ļ�ֵ��
Q��H20���Ա���NVLINK����ǰ����Ҫ��Ӱ������
A������A\H100ʱ�����������绥����������������11�·ݶ�H800����������ȡ���������ơ������������������⣬��μȲ����߶˿������Dz��ж�ҵ�������������Ŀ����ﵽA\H100�����ܡ�NV���NVLINK���以�������£��ѵ����������ܣ���һ���õ���ҵģʽ��
Q��H20��ɼ�Ⱥ��������HW�ıȽϣ�
A������������ƿ������������ƿ�������以��910B�Ļ���������H20��һ�룬���以�������½�һ�롣�������以����Ӣΰ����һ�ְ�IB��������û��������������������400��800G��Ⱥ��������������ıȽϴ�
Q���N�ڿ������ܶԱ�A100�����������������
A��1���������棬���õ��������棬�����ĸ߶��������Ǻ����������˾�����ڹ�˾�������������Ǻ����ѵģ�NV�ij���֮ǰ������Ӧ���ܼ����Բ�������ţ�����NV������ƽ̨��ʹ�÷�������õġ�
2�����ڿ��Ŀͻ��ڻ�������˾�����Dz�������ҵ�������ǿ�Դ��������������Ϊÿ����������˾���÷�ʽ��ͬ������һЩ�����������û�����������ƽ̨��Ǩ�����䵽���ڵĿ����棬����ɱ�Ǩ�Ƴɱ��Ƚϵ͡���ҶԻ�������ҵ�ܹ�ע������оƬ��ҵ����Ҳ�ܹ�ע����Ϊ����NV�У�������������������ģ�û����ҵ������Ӱ�죬�������С������������ڱ�Ӳ�����öࡣ
Q��17�Ž����µ�֮����H20������ת���𣿻����ٴ������µ��أ�
A�������Ժ�ö���ȡ�����ˣ�NV��ȡ��������H20�Ķ������������ģ�����ͬ�������
Q���˸�����������𣿿ͻ�����Ҫ4���ҵ�����䣿
A��Ӣΰ��Ŀ����ڻ�������˾�����䵽С����-����������Ҫ����ʱ�䣬��������Ե�С�����ǰ��ꡣ���Ľ���Ӣΰ��������ɣ���������⣬��û���·��������̣�������������������ԣ��·���������������С�����������ԣ�����С������Ӧ���뻥����ͬ��������ɹ���
Q����Ҵ�ѵ��ģ�͵ĽǶȣ������ǿ�INT8���ǿ�FP16������FP32���о�˵���ܶ࣬�������й�����Ŀ���Ҫ�ǿ��ĸ�ָ��������أ�
Q����Ҫ��FP32��FP64��FP16�ǹ���������ƹ���ԭ��û�취�ﵽ���������������㣬����FP32��FP64��Ӣΰ�����������FP16�����������������ģ�Ϳ�ܣ�FP16���ǿ����õģ�������һ��ѵ����������������FP32��FP64��
Q�����H100���Ƚ�оƬ��NV��ͨ������Գɱ����������أ�
A����Ӫ�ɱ��������뿨�IJɹ������������ȵġ���һ��ͨ������������H100�Ŀ�����Ӫ�ɱ�����H800�ijɱ���ͬ���ռ䡢���ġ���Ա���÷��棬���ķ��ö��Ǻܸߵġ�H20��H100������һЩ�½������DZ�A100�������٣�ͨ��H20������δ��������ʹ�õijɱ�����A100��3-4������H100��һЩ��
Q��H20ʹ��Һ�䷽����
A��H20�Ƿ��䣬Һ�仹��H100,750w���ġ�H20����2-3�ſ���������A100��3-4����
Q��H20�������ԭ�ȵ�H800�������ӹ��ļ�ɢ��������
A��H20��ɢ�Ȼ����H800����Ϊ���������ĵͣ�ɢ�Ȼ�͵ġ�
Q������Ӣΰ�����˺Ϲ��Ʒ���������ڵ����������£��Dz�����ζ��ͬ��������Ⱥ��Ҫ����ķ�������
A����ģ�H20���ºܶ������ԭ���ù��ڵ��û�ʵ��һЩ�ѵ���
Q���������㹻����Դ�Ͳ������ܺģ�����H20������Ⱥ�����ܷ�ﵽ����H100������Ⱥ������
A�����Եġ�
����������������Դ���缰����ý��ƽ̨��ת��Ŀ�����ڴ��ݸ�����Ϣ�����������߸��˹۵㣬��ȷ�����µ�ȷ�ԣ������ַ���Ȩ���֪�����ǽ���24Сʱ��ɾ����
H20 ƽ̨NVQD02��ͷ
- �����
- EPDM�ܷ�
- �������ӻ�Ͽ�
- Cvֵ�ߣ���������ѹ��
- ����������������
- ɫ������������ͷ��ɫ��Ͳ������ͷ��ɫ�ܷ�
- 100% �������
- ���: NVQD02��NVBQD02
H20 ƽ̨NVBQD02ä���ͷ
- �����
- EPDM�ܷ�
- �������ӻ�Ͽ�
- Cvֵ�ߣ���������ѹ��
- ����������������
- ɫ������������ͷ��ɫ��Ͳ������ͷ��ɫ�ܷ�
- 100% �������
- ���: NVQD02��NVBQD02

��������
�����������弼������˾�ǵ���˹�й���������ǩԼ�����̡���Ʒ����FD83ȫ����������ͷ��UQDϵ��Һ����ٽ�ͷ��EHW194 EPDMҺ�����ܡ���ŷ���ѹ�����¶ȴ�������Manifold�������ͼ��ɷ����ڹ������־��á��������㡢˫̼���»���ս�ԵĽ���㣬��˾�۽��齨�����ʡ�����ḻ��Һ�乤��ʦ�Ŷӣ�Ϊ�ͻ��ṩԽ�Ĺ�����ƺ�ǿ��Ŀͻ�����
��˾��Ʒ���ǣ�����˹Һ��������������EPDM���ܡ���ŷ���ѹ�����¶ȴ�������Manifold��
δ����˾��չ�滮����������Һ�������ʩ����������ң��߱��������䵥Ԫ��CDU�������β��·��SFN����Manifold��רҵ�з��������������
- ��Ի���ʽ��������Manifold/�ڵ㡢CDU/����·��Ӧ�ó������ṩ��ͬ�ھ���������ʽ���ֶ���ȫ�Զ�������������
- ��Ը߿��ú��ܶ�Ҫ��ĵ�Ƭʽ���ܣ����ṩ���������Զ�У������������ä������������ʵ����С�ռ�ľ��Խӡ�
- ����OCP��ȫ�´����UQD/UQDBͨ�ÿ���������Ҳ���״�����, ֧��ȫ��Χ�ڵĴ�����������
|




