|
 |
|
||||||
|
|
|
|
今年,马斯克用全球最大AI超算Colossus轰动了整个世界。
这台超算配备了10万张英伟达H100/H200显卡,并预计未来即将扩展到20万张。
自此,AI巨头们倍感压力,数据中心大战火上浇油。巨头们纷纷酝酿着各自的建造计划。
最近,LessWrong网站上发表了一篇博客,根据公开数据对英伟达芯片的产量、各个AI巨头的GPU/TPU数量进行了估计,并展望了芯片的未来。 博客地址:https://www.lesswrong.com/posts/bdQhzQsHjNrQp7cNS/estimates-of-gpu-or-equivalent-resources-of-large-ai-players#Nvidia_chip_production
芯片数量估算总结
毋庸置疑,英伟达早已跃升为数据中心GPU的最大生产商。 11月21日,英伟达发布的2025财年第三季度财报预计,2024自然年的数据中心收入将达1100亿美元,比2023年的420亿美元增长了一倍多,2025年有望突破1730亿美元。
那么,2024年英伟达实际产量是多少?目前,关于这一数据来源较少,有些甚至还对不上。 不过,有估算称2024年第四季度将生产约150万块Hopper GPU。不过这包括一些性能较低的H20芯片,因此是一个上限值。 根据季度间数据中心收入比例推测,全年生产总量可能上限为500万块――这是基于每块H100等效芯片收入约2万美元的假设,而这个单价似乎偏低;如果使用更合理的2.5万美元计算,实际产量应该在400万块左右。 这一数据与年初估计的150万至200万块H100生产量存在差异。目前尚不清楚这一差异是否可以归因于H100与H200的区别、产能扩大或其他因素。 但由于这一估算与收入数据不一致,选择使用更高的数字作为参考。
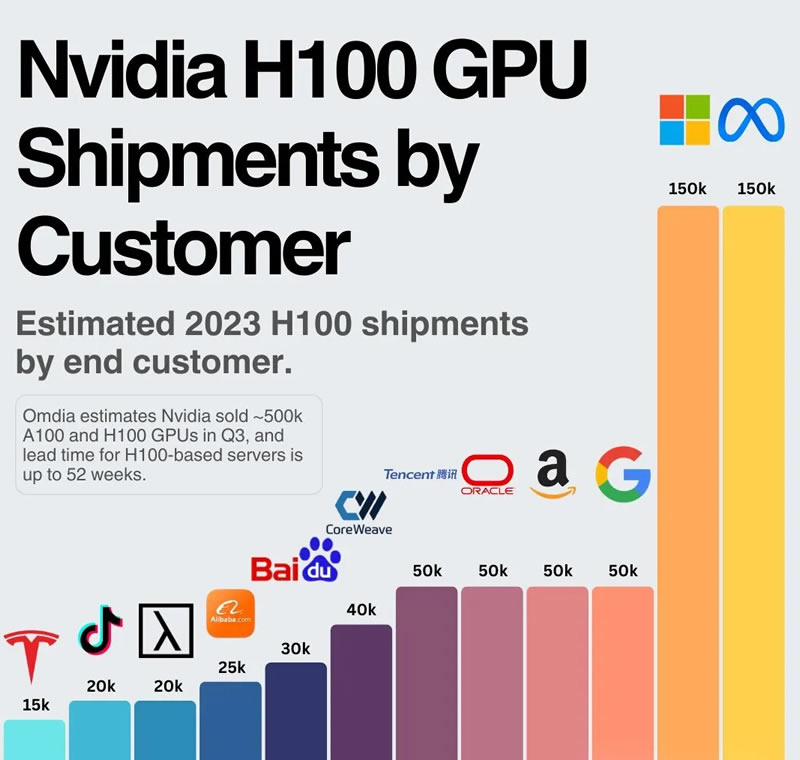
为了评估目前以及未来谁拥有最多的计算资源,2023年之前的数据对整体格局的影响有限。 这主要是因为GPU性能本身的提升,以及从英伟达的销售数据来看,产量已经实现了大幅增长。 根据估算,微软和Meta在2023年各自获得了约15万块H100 GPU。结合英伟达的数据中心收入,2023年H100及同等级产品的总产量很可能在100万块左右。
截止2024年底,微软、Meta、谷歌、亚马逊、xAI将拥有多少块等效H100?2025年他们又将扩展到多少块GPU/TPU?
微软很可能就是英伟达这两年的最大客户,这一判断基于以下几个因素:
仅从英伟达收入的贡献来看,亚马逊、谷歌无疑是落后于微软Meta。然而,这两家公司的情况有着显著差异。
谷歌已经拥有大量自研的定制TPU,这是内部工作负载的主要计算芯片。
去年12月,谷歌推出了下一代迄今为止最强大的AI加速器TPU v5p。
今年,xAI在基础设施搭建中,最为标志性事件便是――122天建成了10万块H100组成的世界最大超算。
最新2024 AI现状报告对Blackwell采购量进行了估算:
大型云计算公司正在大规模采购GB200系统:微软介于70万到140万块之间,谷歌40万块,AWS 36万块。据传OpenAI独自拥有至少40万块GB200。
此外,也包括一些英伟达重要的非美国客户。
在全面了解各家手握多少GPU/TPU算力之后,下一个问题是,这些算力将用在哪?
巨头们训练模型用了多少算力? 以上都讨论的是关于各个AI巨头总计算能力的推测,但许多人可能更关心最新前沿模型的训练使用了多少计算资源。
以下将讨论OpenAI、谷歌、Anthropic、Meta和xAI的情况。
但由于这些公司要么是非上市企业,要么规模巨大无需披露具体成本明细(比如谷歌,AI训练成本目前只是其庞大业务的一小部分),因此以下分析带有一定的推测性。 2024年OpenAI的训练成本预计达30亿美元,推理成本为40亿美元。
谷歌的Gemini Ultra 1.0模型使用了约为GPT-4的2.5倍的计算资源,发布时间却晚了9个月。其所用的计算资源比Meta的最新Llama模型高25%。
尽管谷歌可能拥有比其他公司更多的计算能力,但作为云服务巨头,它面临着更多样的算力需求。与专注于模型训练的Anthropic或OpenAI不同,谷歌和Meta都需要支持大量其他内部工作负载,如社交媒体产品的推荐算法等。
Llama 3所用计算资源比Gemini少,且发布时间晚8个月,这表明Meta分配给前沿模型的资源相较OpenAI和谷歌更少。 据报道,xAI使用了2万块H100训练Grok 2,并计划用10万块H100训练Grok 3。
作为参考,GPT-4据称使用2.5万块A100进行了90-100天的训练。
考虑到H100的性能约为A100的2.25倍,Grok 2的训练计算量约为GPT-4的两倍,而Grok 3则预计达到其5倍,处于计算资源利用的前沿水平。
? 微信扫一扫
These numbers are all estimates I’ve made from publicly available data, in limited time, and are likely to contain errors and miss some important information somewhere. Nvidia chip production Data Center revenues are overwhelmingly based on chip sales. 2025 chip sales are estimated to be 6.5-7m GPUs, which will almost entirely be Hopper and Blackwell models. I have estimated 2m Hopper models and 5m Blackwell models based on the proportion of each expected from the CoWoS-S and CoWoS-L manufacturing processes and the expected pace of Blackwell ramp up. 2024 production Previous production Based on estimates that Microsoft and Meta each got 150k H100s in 2023, and looking at Nvidia Data Center revenues, something in the 1m range for H100 equivalent production in 2023 seems likely. GPU/TPU counts by organisation Numerous sources report things to the effect that “46% of Nvidia’s revenue came from 4 customers”. However, this is potentially misleading. If we look at Nvidia 10-Qs and 10-Ks, we can see that they distinguish between direct and indirect customers, and the 46% number here refers to direct customers. However, direct customers are not what we care about here. Direct customers are mostly middlemen like SMC, HPE and Dell, who purchase the GPUs and assemble the servers used by indirect customers, such as public cloud providers, consumer internet companies, enterprises, public sector and startups. The companies we care about fall under “indirect customers”, and the disclosures around these are slightly looser, and possibly less reliable. For fiscal year 2024 (approx 2023 as discussed) Nvidia’s annual report disclosed that “One indirect customer which primarily purchases our products through system integrators and distributors [..] is estimated to have represented approximately 19% of total revenue”. They are required to disclose customers with >10% revenue share[3], so either their second customer is at most half as big as the first, or there are measurement errors here[4]. Who is this largest customer? The main candidate seems to be Microsoft. There are sporadic disclosures on a quarterly basis of a second customer exceeding 10% briefly[5], but not consistently and not for either the full year 2023 or the first 3 quarters of 2024[6]. Estimating H100 equivalent chip counts at year end 2024 There are other estimates of customer sizes - Bloomberg data estimates that Microsoft makes up 15% of Nvidia's revenue, followed by Meta Platforms at 13% of revenue, Amazon at 6% of revenue, and Google at about 6% of revenue - it is not clear from the source which years this refers to. Reports of the numbers of H100 chips possessed by these cloud providers as of year end 2023 (150k for Meta and Microsoft, and 50k each for Amazon, Google and Oracle) align better with the Bloomberg numbers. An anchoring data point here is Meta’s claim that Meta would have 600k H100 equivalents of compute by year end 2024. This was said to include 350k H100s, and it seems likely most of the balance would be H200s and a smaller number of Blackwell chips arriving in the last quarter[7]. If we take this 600k as accurate and use the proportion of revenue numbers, we can get better estimates for Microsoft’s available compute as being somewhere between 25% and 50% higher than this, which would be 750k-900k H100 equivalents. Google, Amazon Google already has substantial amounts of its own custom TPUs, which are the main chips used for their own internal workloads[8]. It seems very likely that Amazon’s internal AI workloads are much smaller than this, and that their comparable amounts of Nvidia chips reflect mostly what they expect to need to service external demand for GPUs via their cloud platforms (most significantly, demand from Anthropic). Let’s take Google first. As mentioned, TPUs are the main chip used for their internal workloads. A leading subscription service providing data on this sector, Semianalysis, claimed in late 2023 that “[Google] are the only firm with great in-house chips” and “Google has a near-unmatched ability to deploy AI at scale reliably with low cost and high performance”, and that they were “The Most Compute Rich Firm In The World”. Their infrastructure spend has remained high[9] since these stories were published. Taking a 2-1 estimate for TPU vs GPU spend[9] and assuming (possibly conservatively) that TPU performance per dollar is equivalent to Microsoft’s GPU spend I get to numbers in the range of 1m-1.5m H100 equivalents as of year end 2024. Amazon, on the other hand, also has their own custom chips, Trainium and Inferentia, but they got started on these far later than Google did with its TPUs, and it seems like they are quite a bit behind the cutting edge with these chips, even offering $110m in free credits to get people to try them out, suggesting they’ve not seen great adaptation to date. Semianalysis suggest “Our data shows that both Microsoft and Google’s 2024 spending plans on AI Infrastructure would have them deploying far more compute than Amazon” and “Furthermore, their upcoming in-house chips, Athena and Trainium2 still lag behind significantly.” What this means in terms of H100 equivalents is not clear, and numbers on the count of Trainium or Trainium2 chips are hard to come by, with the exception of 40,000 being available for use in the free credits programme mentioned above. However, as of mid 2024 this may have changed - on their Q3 2024 earnings call CEO Andy Jassy said regarding Trainium2 “We're seeing significant interest in these chips, and we've gone back to our manufacturing partners multiple times to produce much more than we'd originally planned.” At that point however, they were “starting to ramp up in the next few weeks” so it seems unlikely they will have huge supply on board in 2024. XAI 2025 - Blackwell The Google and AWS numbers here are consistent with their typical ratio to Microsoft in Nvidia purchases, if we take 1m as the Microsoft estimate. This would also leave Microsoft at 12% of Nvidia total revenues[10], consistent with a small decline in its share of Nvidia revenue as was seen in 2024. No Meta estimate was given in this report, however Meta anticipates a “"significant acceleration" in artificial intelligence-related infrastructure expenses next year” suggesting its share of Nvidia spending will remain high. I have assumed they will remain at approximately 80% of Microsoft spend in 2025. For XAI, they are not mentioned much in the context of these chips, but Elon Musk claimed they would have a 300k Blackwell cluster operational in summer 2025. Assuming some typical hyperbole on Musk's part it seems plausible they could have 200k-400k of these chips by year end 2025. How many H100s is a B200 worth? For the purpose of measuring capacity growth, this is an important question. Different numbers are cited for training and for inference, but for training 2.2x is the current best estimate (Nov 2024). For Google, I have assumed the Nvidia chips continue to be ? of their total marginal compute. For Amazon, I have assumed they are 75%. These numbers are quite uncertain and the estimates are sensitive to them. It is worth noting that there are still many, many H100s and GB200s unaccounted for here, and that there could be significant aggregations of them elsewhere, especially under Nvidia’s 10% reporting threshold. Cloud providers like Oracle and other smaller cloud providers likely hold many, and there are likely some non-US customers of significance too, as Nvidia in Q3 2025 said that 55% of revenue came from outside the US in the year to date (down from 62% the previous year). As this is direct revenue, it may not all correspond to non-US final customers. Summary of estimated chip counts [11] OpenAI 2024 training costs were expected to reach $3bn, with inference costs at $4bn. Anthropic, per one source, “are expected to lose about ~$2B this year, on revenue in the high hundreds of millions”. This suggests total compute costs more on the order of $2bn than OpenAI’s $7bn. Their inference costs will be substantially lower, given their revenue mostly comes from the API and should have positive gross margins, this suggests that most of that $2bn was for training. Let’s say $1.5bn. A factor of two disadvantage for training costs vs OpenAI does not seem like it would prohibit them being competitive. It also seems likely, as their primary cloud provider is AWS, which as we’ve seen has typically had fewer resources than Microsoft, which provides OpenAI’s compute. The state of AI report mentioned earlier suggested 400k GB200 chips were rumoured to be available to OpenAI from Microsoft, which would exceed AWS 'entire rumoured GB200 capacity and therefore likely keep them well above Anthropic’s training capacity. Google is less clear. The Gemini Ultra 1.0 model was trained on approximately 2.5x the compute of GPT-4, but published 9 months later,, and 25% more than the latest Llama model. Google, as we have seen, probably has more compute available than peers, however as a major cloud provider and a large business it has more demands[12] on its compute than Anthropic or OpenAI or even Meta, which also has substantial internal workflows separate from frontier model training such as recommendation algorithms for its social media products. Llama 3 being smaller in compute terms than Gemini despite being published 8 months later suggests Meta has so far been allocating slightly less resources to these models than OpenAI or Google. XAI allegedly used 20k H100s to train its Grok 2, and projected up to 100k H100s would be used for Grok 3. Given GPT-4 was allegedly trained on 25,000 Nvidia A100 GPUs over 90-100 days, and a H100 is about 2.25x an A100, this would put Grok 2 at around double the compute of GPT-4 and project another 5x for Grok 3, putting it towards the leading edge. Note that not all of this has historically come from their own chips - they are estimated to rent 16,000 H100s from Oracle cloud. If XAI is able to devote a similar fraction of its compute to training as OpenAI or Anthropic, I would guess its training is likely to be similar in scale to Anthropic and somewhat below OpenAI and Google.
Thanks to Josh You for feedback on a draft of this post. All errors are my own. Note that Epoch have an estimate of numbers for 2024 here which mostly lines up with the figures I estimated, which I only found after writing this post, though I expect we used much of the same evidence so the estimates are not independent. ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^
关于我们 北京汉深流体技术有限公司 是丹佛斯中国数据中心签约代理商。产品包括FD83全流量双联锁液冷快换;液冷通用快速接头UQD & UQDB;OCP ORV3盲插快换接头BMQC;EHW194 EPDM液冷软管、电磁阀、压力和温度传感器。在国家数字经济、东数西算、双碳、新基建战略的交汇点,公司聚焦组建高素质、经验丰富的液冷工程师团队,为客户提供卓越的工程设计和强大的客户服务。 公司产品涵盖:丹佛斯液冷流体连接器、EPDM软管、电磁阀、压力和温度传感器及Manifold。 - 针对机架式服务器中Manifold/节点、CDU/主回路等应用场景,提供不同口径及锁紧方式的手动和全自动快速连接器。
|
|