|
 |
|
||||||
|
|
|
|
虽然行业标准的OSFP(八进制小型可插拔)模块成功支持了400Gbps、800Gbps和1.6Tbps的光插拔模块[1],但每个机架单元(RU)限制为32个模块,通常需要2个RU才能达到102.4Tbps,4个RU才能达到204.8Tbps的交换容量。尽管联合封装光学(CPO)和车载光学(OBO)被提出以提高带宽密度,但这些方法在现场服务性、可扩展性和制造性方面带来了重大挑战,使其难以在超大规模环境中广泛部署[2]。 为应对这些挑战,Arista Networks与45个以上行业合作伙伴的生态系统共同推出了eXtra密集的可插拔光学(XPO)[3]。XPO代表了一类专为下一代AI数据中心结构设计的新型光学可插拔模块。每个XPO模块通过64条电线提供12.8Tbps带宽,并集成液冷冷板,支持400W+模块功耗。 XPO模块比OSFP宽约2.7×,每个模块带宽提升8倍,使单个开放式机架单元(1OU)垂直空间内可实现高达204.8Tbps的切换容量——相比OSFP前面板密度增加了4×。 XPO可插拔模块保留了现场插拔的优势,使得光学模块能够快速更换或升级,无需维护整个开关,并最大限度地减少停机时间。它还支持按增长付费的部署模式,并兼容多种光纤架构——包括DR、FR、LR、SR和ZR——以支持多样化的网络配置,同时提供更高的运营灵活性。 人工智能基础设施需求增长
核心挑战源于一个简单的现实:AI数据中心需要比传统云数据中心多出数量级的带宽。这种需求吞吐量的剧增无法仅靠渐进式改进来解决;这需要对互联技术进行根本性的重新评估。为了支持支持现代AI工作负载的分布式训练集群和庞大数据集,网络结构的每个组件都必须重新设计,以实现更高的性能、更高的密度和更高的效率。本文概述了这一人工智能驱动转型带来的新需求,并介绍了专门设计以应对这些挑战的光学架构。 人工智能网络光互连的要求
极限带宽 高可靠性 液冷 能效 前所未有的密度 基于这五个基本需求,显然广泛采用的OSFP模块并不适合AI 驱动数据中心的新兴需求。现有光学技术与下一代人工智能基础设施需求之间的差距凸显了光互连设计新架构方法的必要性。 解决方案概述:Arista XPO 可插拔光学模块
XPO模块的主要规格和优势直接对应上述五项关键要求: 带宽:每个XPO模块提供12.8Tbps带宽,配置为64个通道,速度为200Gbps,支持高基数、无阻塞的网络结构,支持最苛刻的AI集群。 可靠性:通过优化电气通道、热管理和整体组件架构,XPO 提高了每传输比特的可靠性,减少作业中断并提升整体系统可用性。 冷却:XPO模块集成了液冷冷板,为液冷数据中心环境提供了高效的热解决方案,并实现高功率光学元件的直接散热。 功耗:设计采用高质量线性接口通道,提升信号完整性,使得依赖复杂且耗电量大的传统光学元件更低功耗。 密度:XPO提供OSFP的8×带宽,OSFP前面板密度的4倍,使每个开门机架单元(1OU)的交换吞吐量高达204.8Tbps,并树立了可插拔光模块密度的新基准。
图1:OSFP与XPO的比较,突出XPO相较8X OSFP在密度上的提升
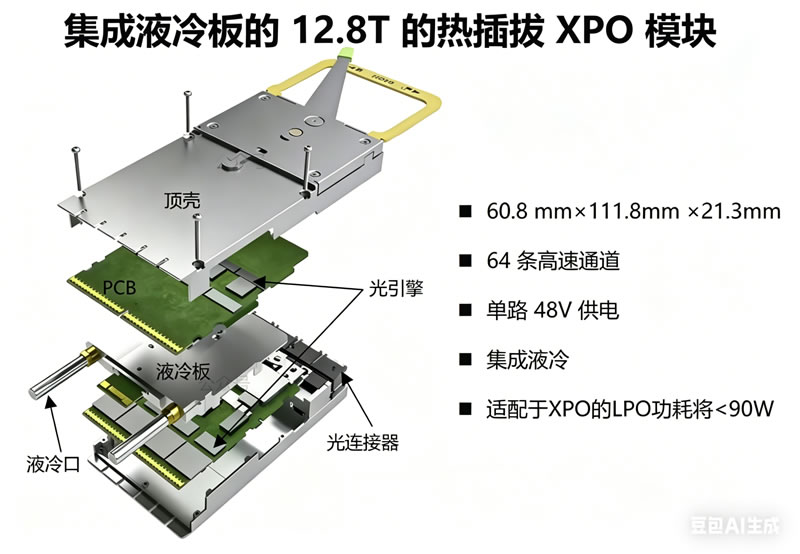
一. 尺寸与间距: 该模块采用紧凑的机械形态,尺寸为宽度60.8毫米×长111.8毫米×高度21.3毫米, 实现了高前面板密度。 二. 双拨片卡:在模块外壳内部,XPO架构包含两块独立的32通道印刷电路板(PCB),称为拨片卡。 三. 腹对腹布局: 这两张相同的牌(牌1和牌2)以“腹对腹”排列,朝内朝向共享的中央元素。 高功率发热元件(如发射电路和激光驱动器)安装在PCB内向的“热”侧,而低功率元件(如接收电路和控制逻辑)安装在朝外的“冷”侧。 四. 弹壳抛出机构: 由于电接触点数量众多,插入和 拆卸需要较大的力。XPO模块采用机械弹射器配备释放拉片,提供1:11的机械杠杆,帮助操作员 在插入时与主笼平稳啮合。
一. 中央冷板:液冷板物理夹在两块拨片的“热”侧之间,同时冷却两块电路板。 二. 热能力:该设计高效去除超过400W的高功率模块热量,轻松支持XPO模块内8颗1.6Tbps的ZR光学元件等高强度应用。通过采用40-45°C的温水液冷,XPO使部件温度比风冷同类产品低20°C至25°C。 三.流体接口:该模块集成了流体通道,并通过盲对、快速断开液体连接器连接到主机系统的冷却歧管。这些无滴水连接器额定匹配500次,支持从低功率模块0.25升/分钟(LPM)到高功率模块0.7 LPM的动态流量。 电气接口与50伏电源传输 一. 干净线性信道:高速发射(Tx)和接收(Rx)信号被分隔在拨片卡的两侧,以减少串扰,提供一个优化的线性信道,非常适合线性驱动插拔光学(LPO)。 二.专用电源/控制连接器:为防止电源噪声耦合到高速数据通道,电源和低速控制信号(如I2C/I3C、重置和中断)通过模块中央的完全独立专用卡边连接器传输。 三.50V直流架构:传统插拔式依赖3.3V直流输入,该输入对高功率光学器件产生巨大电流。XPO直接从机架母线引入46V到53V的直流输入(名义上为48V或50V)。这种高压输入显著降低了所需的额定电流和电源连接器的物理尺寸。 四.主板简化:通过利用直接位于模块拨片卡上的板载48V转3.3伏电压调节器,XPO消除了在开关主板上安装笨重且最坏情况配置电压调节器的需要,最大化了整体系统的可靠性。 比较分析:量化XPO相较于OSFP的优势
当这种密度优势应用于标准ORv3(HPR)液冷机架[4]的系统层面时,其益处更加显著。下表比较了基于各光学标准的完整机架。这一比较揭示了关于总拥有成本(TCO)的重要见解。液冷基础设施是一项可贵的资本投资,为了证明这笔费用,机架部署通常必须以120千瓦或更高的功率密度为目标。 基于OSFP的机架最大功耗约为32kW,严重低估了现有的冷却基础设施。相比之下,基于XPO的机架,功率约为128kW,充分发挥机架的液冷能力。这使得冷却和电力传输基础设施能够高效摊销到更大的计算负载上。这一点在表1中总结。
考虑一个由512个XPU(如GPU或其他加速器)组成的AI集群,连接在一个可扩展领域。假设每个XPU带宽为25.6Tbps,该扩展域需要64台交换机,每台容量为204.8Tbps。采用现有的OSFP技术,每4个机架单元提供204.8Tbps的传输速度,网络需要八个交换机架来提供必要的连接。相比之下,基于XPO的架构仅用两个交换机架即可支持同一集群,因为XPO在单个机架单元内支持204.8Tbps的交换容量,实现4×密度提升。 在超大规模上,这种效率提升具有深远影响。考虑一个400兆瓦的AI数据中心,支持128,000个XPU。在此情景中,我们假设一个扩展网络,每个XPU为12.8Tbps,一个扩展网络为每个XPU1.6Tbps,加速器通过三层Clos拓扑相互连接。在这种情况下,每个机架的交换容量大约为 OSFP为1.64Pbps,而XPO为6.55Pps,体现了XPO架构带来的显著密度优势。
或者,拥有现有数据中心的运营商可以利用这一密度优势,提高每栋建筑的加速器密度,最大化现有基础设施和房地产的利用率。此外,XPO支持的高基交换机实现了更简洁的扩展网络拓扑结构,层数更少,往返延迟更低,直接提升了大规模AI训练工作负载的性能和效率。 核心创新与平台多样性 一.现有技术的应用:XPO通过利用现有的光子和硅芯片技术,支持提升每个模块的容量。这种方法降低了采用风险,使生态系统能够基于成熟、可靠且具成本效益的制造流程进行建设。 二. 集成冷板:XPO通过嵌入两张板板之间的冷板,采用了本地液冷系统,这两片板板呈腹部对腹部排列。该设计实现了光学元件和DSP直接高效传热到液冷系统的能力。 三. 干净线性信道:通过CPC飞越电缆和优化的边缘连接器引脚,实现了更优的信号完整性。这种干净、低损耗的电信道减少了对高功耗数字信号处理(DSP)的需求,从而降低了整体功耗。 四. 能效:除了支持线性通道架构外,XPO还通过直接利用50V直流母线电压作为模块供电,提升电力传输效率,最大限度地减少系统内的功率转换损耗。 五. 提升可靠性:可靠性通过多种因素共同提升,包括减少元件数量、集成冷板实现的较低工作温度、最小化温度变化以及通过优化的电气通道提升信号完整性。 六. 高密度:XPO模块密度通过使用MPO-16连接器优化模块物理尺寸以实现最大光学密度。这种配置也符合高速电气系统连接器中可用的最高密度,从而实现高效的布线和封装。这种务实的物理设计是实现相较OSFP提升4×密度的关键因素。 除了这些核心创新外,XPO平台还设计了最大灵活性,使其能够适应不断演进的光学技术和未来的行业标准。 结论:开启下一代人工智能网络 XPO架构通过专门设计的可插拔模块应对这些挑战,优化了超大规模AI 基础设施。通过结合双拨片机械架构、集成液冷冷板、干净的线性电通道和高压功率传输,XPO大幅提升光学密度,同时保持可插拔光学器件的操作灵活性和可维修性优势。 XPO每模块12.8Tbps,每台1OU交换机最高可达204.8Tbps,前面板密度比OSFP提升4×,实现交换机机架占地约75%,同时显著降低基础设施成本和网络复杂度。在超大规模阶段,这些改进转化为资本效率、运营简化和整体系统性能的显著提升。 通过从零开始重新思考光模块架构,XPO为下一代AI网络基础设施提供了可扩展的基础,使数据中心运营商能够构建更高容量、更高效、更可靠的网络,以支持人工智能快速增长的需求。
参考文献 [二]《释放人工智能与高性能计算中共封光学的潜力:机遇与挑战》,Sunil Priyadarshi,IEEE通信杂志,2026年2月刊,https://ieeexplore.ieee.org/document/11303304 [三]https://xpomsa.com [四]https://www.opencompute.org/wiki/Open_Rack/SpecsAndDesigns
下面讲讲 XPO / NPO / CPO 三者到底是什么
先看懂这三个技术 - XPO(eXtra-dense Pluggable Optics) - NPO(Near-Packaged Optics) - CPO(Co-Packaged Optics) 注意,三者虽然都有“PO”,但XPO的“P”是可插拔的“P” 核心区别对比 1. 物理位置 & 形态 - XPO:前面板可插拔,大模块(60.8mm宽) 2. 速率 & 密度(2026) - XPO:单模块 12.8Tbps(64×200G) 3. 功耗(关键) - XPO:单模块 ~400W(液冷刚需) 4. 可维护性 - XPO:? 热插拔、单换模块 5.XPO与CPO,NPO的关系 XPO 是传统“可插拔光模块”阵营为了对抗甚至取代 CPO/NPO 架构,而进化出的新形态。 路线之争:CPO 和 NPO 属于“板载集成路线”,试图用集成化换取功耗和密度;而 XPO 属于“前面板可插拔路线”,试图在保留运维便利性的同时,通过液冷和超高通道密度来逼近CPO 的性能。
模块厂商与云厂商对XPO的态度 XPO保住可插拔生态,避免被CPO颠覆 另外不喜欢CPO(共封装光学)“光引擎与芯片绑定”:CPO一旦光模块故障,需更换整板/整机,停机时间长、成本极高。 云厂商要“好运维”,模块厂商要“好生意”,XPO刚好同时满足两边。
共识与未来 - 短期(2026—2028):XPO是AI数据中心主力方案,快速上量。
|
|